國家高速網路與計算中心
國家高速網路與計算中心
【2024 NCHC, NVIDIA, OpenACC 黑客松】— 人工智慧應用成果
[Real-time 3D Scene Graph Construction for Robotic Navigation]
ELSALAB 團隊來自國立清華大學,將 3D Scene Graph Construction 加速了 11 倍!!
* Team Members: Yung Shun Chan, Yu-Zhong Chen, Chon-Hang Lam.
* NVIDIA Mentors: Johnson Sun, Frank Lin.
在智慧機器人領域中,定位與建圖是相當重要的能力,機器人必須精準的分析感測器資訊,並將其應用於後續的導航與決策任務。為了確保後續模組能快速的完成任務,整體處理時間成為一個關鍵重點。
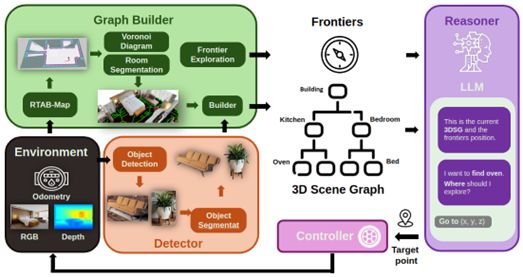
為了讓機器人在未知環境中建立 3D Scene Graph,我們使用 RGB-D 相機,並且透過 YOLO-World 物件偵測模型將物體框出,再利用 SAM 影像分割模型獲取物體的遮罩,最後結合深度資訊,估計出物體在 3D 空間中的位置。
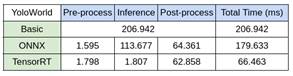
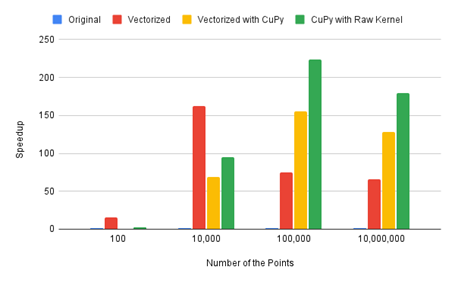
然而原本模型的推論速度較慢,且深度資訊轉換到世界座標的計算效率不足,導致整體系統無法達到 real-time 的成果。因此我們透過 CuPy 快速地部屬程式到 GPU 上面,也使用 TensorRT 加速模型推論。最終,我們成功將速度提升至 5.5 FPS (11 倍)。
更多資訊請看:https://github.com/nqobu/nvidia/tree/main/20241204
[Audio-MAE for Bird Song Pretraining]
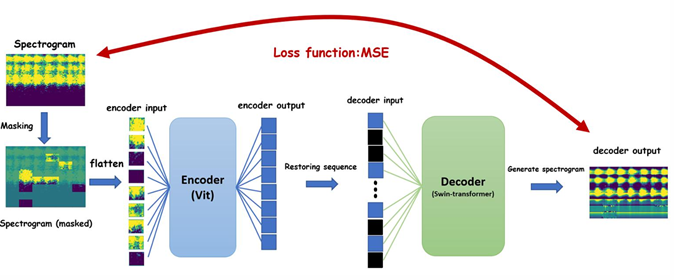
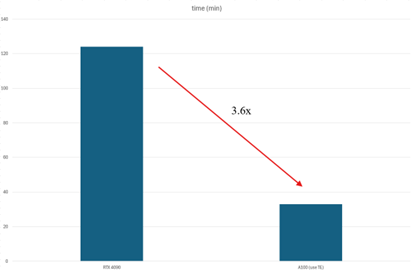
NTUT Birdsong 團隊來自臺北科技大學自動化所陳詩雯實驗室,透過Transformer Engine將 Audio-MAE加速3.6倍!!
* Team Members: Jin-Jia Hu, Yang-Yu Ou, Xin-He Chen, Yi-Yang Syu, Yung-Yu Chen, Shih-Cheng Ma.
* NVIDIA Mentors: Virginia Chen, Iven Fu.
我們團隊致力於解決Deep Learning中 pre-train時間過長的難題,這次選擇 Audio-MAE 作為研究基礎,並以 swin-transformer 和 ViT 作為演算法的核心架構。這次採用 Transformer Engine 來分段處理模型訓練的過程。
透過Transformer Engine技術來實現加速運算:
• 資料類型最佳化:利用 混合精度計算,使用 FP8 或 FP16 取代傳統的 FP32,在提升計算效率的同時降低 GPU 記憶體需求。
• 計算最佳化:透過最佳化模型的計算,確保計算資源的最佳分配,避免運算瓶頸的產生。
• 加速硬體:利用 NVIDIA A100 GPU 的 Tensor core 加速運算,進一步提升AI模型訓練速度。
• 記憶體管理:有效管理 GPU 記憶體,特別是在大規模模型訓練中,避免記憶體瓶頸並減少資料傳輸延遲。
團隊在軟體最佳化方面 達到了 1.3 倍的加速,加上硬體加速,最終實現了 3.6 倍的整體加速。 團隊使用了 兩張 A100 GPU 進行測試,並透過 Nsight system分析 GPU 使用率,深入了解不同 GPU 的限制。