 國家高速網路與計算中心
國家高速網路與計算中心
【2024 NCHC, NVIDIA, OpenACC 黑客松】— 加速運算技術
[以DPU卸載CPU封包傳輸,並利用GPU加速網路處理能力]
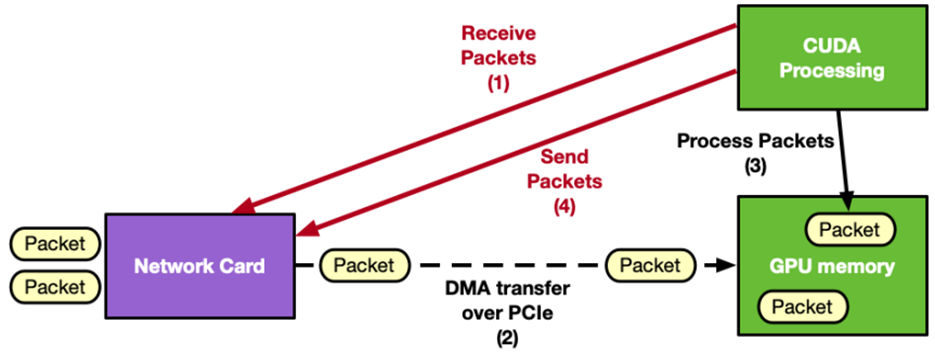
圖一:DPU卸載架構說明
NTHU_LSALAB 團隊來自清華大學周志遠教授超大型系統架構實驗室,嘗試透過DPU(Data Process Unit)元件卸載CPU封包傳輸,透過GPU平行化加速~23%網路處理能力!
* Team Members: Yong Xuan Huang, Bi Shun Ke, Chuan Ming Ou, Jerry Chou.
* NVIDIA Mentors: Kevin Chen, SungTa Tsai.
有鑑於資料中心內的網路傳輸需求日益增加,從過去的100Gbps已經逐步到成長到 200Gbps甚至400Gbps。網路封包需透過CPU進行多層次的解析、轉發與優化。許多研究都指出單一CPU只能支撐到~40Gbps的效能,因此使用CPU已無法滿足高速網路資料的使用情境。
團隊嘗試透過DPU(Data Processing Unit)技術來加強封包傳輸與處理效率應用於目前常見的大語言模型推論情境上。DPU卸載原須經由CPU的傳輸、處理任務,先由GPUnetIO技術直接將封包傳遞至GPU,再直接於GPU處理封包。透過DPU大幅省略CPU與GPU間的資料傳輸成本,形成更直接且高速的資料通道,並降低主機CPU的負擔,使其更專注於高階決策或其他工作。在充分利用GPU平行運算的特性,加速封包篩選、加解密、品質調整 (QoS) 以及特定網路服務的處理後,團隊的研發成果與實驗可將整體處理提昇速度約 23%,更能滿足高頻寬、低延遲的傳輸需求,加強如推論情境的效率。
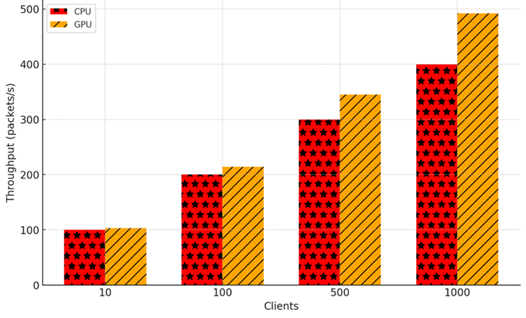
圖二:卸載後處理效率結果。
更多資訊請看:https://github.com/nqobu/nvidia/tree/main/20241204
[Optimize firefly algorithm with cuda]
Team parallel-minds 來自清華大學,將firefly algorithm加速9倍!
* Team Members: 程詩柔、謝之豫、熊恩伶.
* NVIDIA Mentors: Reese Wang.
firefly algorithm應用層面非常多,firefly algorithm 不僅可以應用於路徑預測(導航),還可以優化可再生能源系統(太陽能電池效率最大化),基因調控網絡建模,藥物設計,影像處理等,希望本次Open Hackathons成功優化的版本能夠幫助各種領域中需要使用firefly algorithm的研究。
firefly algorithm 相較於 Particle swarm optimization algorithm,預測準確率較高但是執行時間較久,因為firefly algorithm迴圈時間複雜度非常高為訓練次數 * 模擬螢火蟲個數 * 空間維度 * 模擬螢火蟲個數,所以我們希望能透過cuda去優化firefly algorithm,並成功使用一張gpu計算相比使用2顆cpu全資源計算快上9倍,省電10倍。
